Quick way to scrape websites
In this post I want to show a super quick way to scrape websites using the python
package requests-html and firefox’s developer tools.
requests-html is really just an extension on top of the popular requests library that adds
some html parsing. It supports different ways of traversing the html, including CSS selectors, which
is what we can use Firefox for.
Here’s what a sample scraping script might look like.
from requests_html import HTMLSession
nickname = "tethik"
session = HTMLSession()
r = session.get(f'https://247ctf.com/progress/{nickname}')
# Scrape score
sel = "div.col:nth-child(4) > div:nth-child(1) > div:nth-child(1) > div:nth-child(2) > h4:nth-child(1)"
score = int(r.html.find(sel, first=True).text.replace(",", ""))
# Scrape challs
sel = ".timeline > li > div:nth-child(2) > div:nth-child(1) > div:nth-child(1) > span:nth-child(2) > a:nth-child(1)"
challs = r.html.find(sel)
challs = list(map(lambda ch: ch.text, challs))
print(score, challs)Writing those selectors can be a bit annoying, so that’s where Firefox comes in. The dev-tools allows you to simply right click the element you want to scrape.
As an example, here’s how
Right click on the element that contains the interesting data, then under “Copy” you find CSS Selector.
Note XPath is also an option available for export and is also something that requests-html supports.
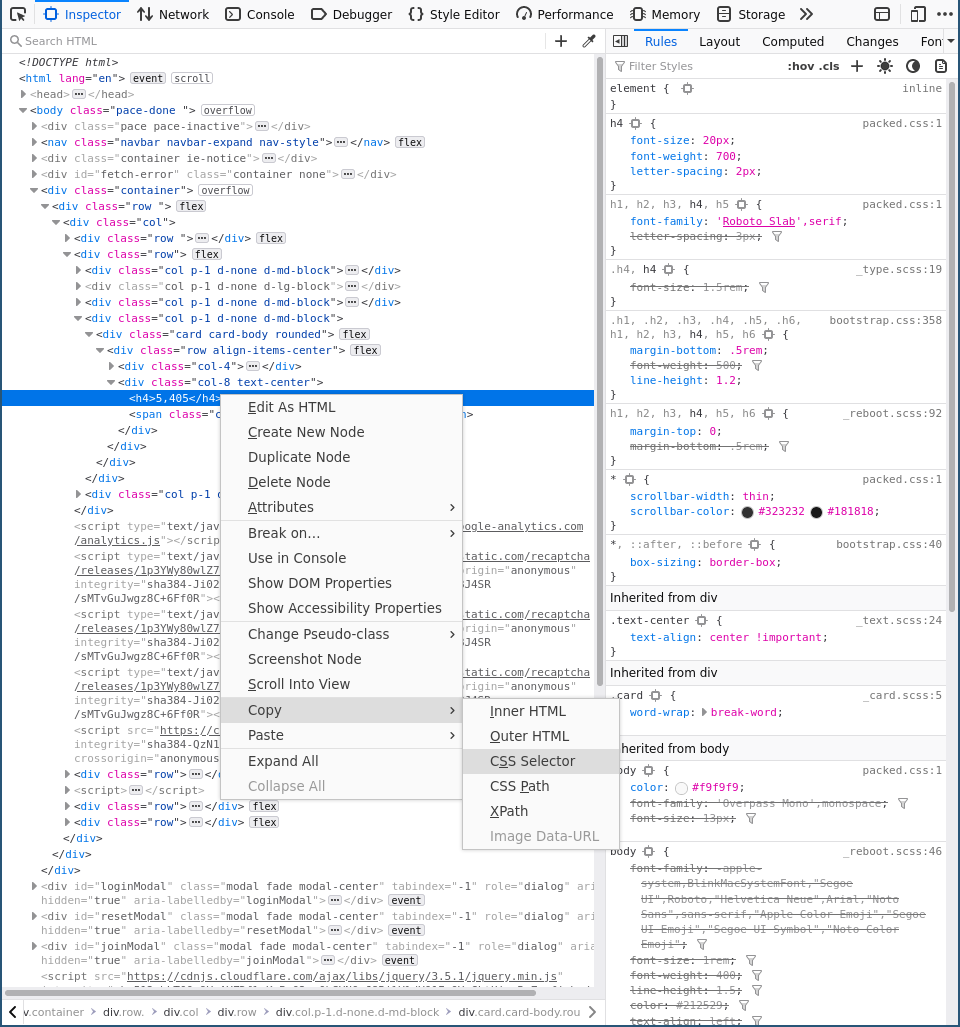
Copy that selector into the script and you’re done. 🎉
Note that if you want e.g. a list of items, you may need to adjust the selector to remove nth-child statements to
get all similar elements.
Also, this method won’t work on sites that are just pure javascript bundles. Check out selenium for more advanced scraping, which actually hooks into a browser.